![10. CKA udemy 강의 정리 - Section 4 [Logging&Monitoring]](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2Fboqpqd%2FbtrVYkXmgds%2FAAAAAAAAAAAAAAAAAAAAAKnqfIC_VNIjoLVcPx7dzjSUShPVwD7b6TyIszYlL7PJ%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1774969199%26allow_ip%3D%26allow_referer%3D%26signature%3D%252F3ZIxzv8eMtaoH8UoWy5ZS1pabs%253D)
쿠버네티스는 여러 노드에 걸쳐 대량의 컨데이터가 작동한다.
$ kubelet top 명령어 로 메트릭을 볼 수는 있지만 이것만으로 실제 쿠버네티스 클러스터를 운영하기에는 부족하기 때문에
모니터링 도구 SaaS(software as a service)를 사용한다. 예) Prometheus, Elastic Stack, Datadog, Dynatrace


모니터링 컴포넌트 소개
cAdvisor: kubelet에 포함되어 노드, 파드, 컨테이너의 리소스 사용률을 수집하는 모듈
metrics server: cAdvisor로부터 정보를 수집하는 도구로, 리소스 메트릭 파이프라인은 metrics server의 정보를 활용함 (이 역할을 수행하던 heapster는 쿠버네티스 버전 1.11부터 더 이상 사용되지 않음)
Prometheus: 서비스 디스커버리, 메트릭 수집(Scrape) 및 저장(TSDB), 쿼리 기능(PromQL 사용), Alert 기능을 제공하는 도구
Grafana: 데이터 시각화 도구(Prometheus를 데이터 소스로 지정)
Monitoring이란?
쿼리 카운트, 에러 카운트, 처리 시간, 서버의 활성 시간과 같은 시스템에 관련된 정량적 수치를
실시간으로 수집, 처리, 집계, 보여주는 모든 행위
- Signal, Telemetry, Trace 등을 수집하고 집계하는 행위 (Logging 포함)
- 임계점을 넘어가는 상태에 대한 알림 및 조치
ex) DB 디스크 사용량 임계점 초과시 알람 발생 및 통지 -> 스토리지 확장
Metrics: 응용 프로그램 및 서비스의 성능과 품질을 측정하는 데 도움이 되는 정량 데이터
- 컨테이너 인프라 환경에서 metric 구분
- system metrics: 파드 같은 오브젝트에서 측정되는 CPU와 메모리 사용량을 나타내는 메트릭
- service metrics: HTTP 상태 코드 같은 서비스 상태를 나타내는 메트릭
모니터링 컴포넌트 소개
cAdvisor: kubelet에 포함되어 노드, 파드, 컨테이너의 리소스 사용률을 수집하는 모듈
metrics server: cAdvisor로부터 정보를 수집하는 도구로, 리소스 메트릭 파이프라인은 metrics server의 정보를 활용함 (이 역할을 수행하던 heapster는 쿠버네티스 버전 1.11부터 더 이상 사용되지 않음)
Prometheus: 서비스 디스커버리, 메트릭 수집(Scrape) 및 저장(TSDB), 쿼리 기능(PromQL 사용), Alert 기능을 제공하는 도구
Grafana: 데이터 시각화 도구(Prometheus를 데이터 소스로 지정)
Kubernetes에서 말하는 Metrics란?
계량이라는 뜻을 가진 Metrics는 Kubernetse에서 수집지표를 뜻함.
즉 kubernetes에서 Monitoring으로 감시하기 위한 대상 자원들을 Metric(메트릭)이라고 부름.
kubernetes Metrics는 4계층으로 분류됨.
Metrics 수집 방법(2)
Metrics를 수집하는 방법을 Pipeline(=Monitoring)이라고 칭한다. Pipeline은 Core metric pipline, Monitoring pipeline 2가지.
1. Core metric pipeline (Resource Metric Pipeline, 리소스 메트릭 파이프라인)
Kubernetes의 Master Node, Worker Node로부터 수집되는 System Metrics에 대한 모니터링을 담당.
kubectl top 명령으로 나오는 결과와 관련있는 Metric을 수집한다.
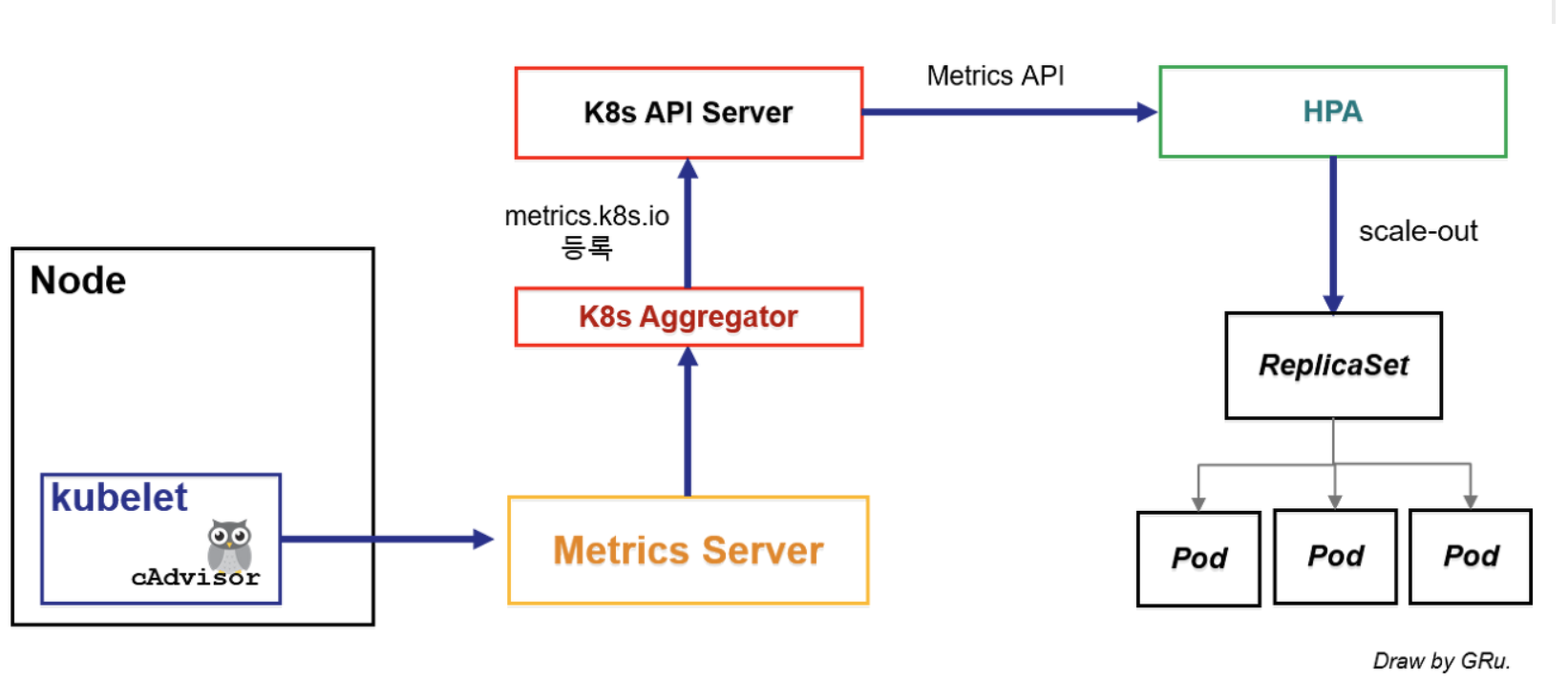
in-memroy 솔루션인 메트릭 정보는 어떻게 수집될까?
쿠버네티스 노드는 kubelet을 통해 파드를 관리하며, 파드의 CPU나 메모리 같은 메트릭 정보를 수집하기 위해 kubelet에 내장된 cAdvisor를 사용 함. cAdvisor는 쿠버네티스 클러스터 위에 배포된 여러 컨테이너가 사용하는 메트릭 정보를 수집한 후 이를 가공해서 kubelet에 전달하는 역할을 한다. metric 설치후에 kubectl top node나 kubectl top pod하면 CPU와 Memory 정보를 노출해주고, 스케일링 설정이 되어있다면 자동스케일링에 활용한다. metrics-server를 통해 수집된 모니터링 정보를 메모리에 저장하고 API 서버를 통해 노출해 kubectl top, scheduler, HPA와 같은 오브젝트에서 사용하는데, 다만 이러한 정보는 순간의 정보를 가지고 있고, 다양한 정보를 수집하지 않으며, 장시간 저장하지 않는다는 단점이 있다.
2. Monitoring pipeline (Full Metric Pipeline, 완전한 메트릭 파이프라인)
Kubernetes를 구성하는 Node이외에 별도의 Addon을 사용해서 모니터링 데이터를 수집

쿠버네티스에서 직접적으로 관여하지 않으며, 주로 Kubernetes Cluster 사용자들이 필요한 자원을 모니터링 하는데 사용된다. 별도의 외부 서드파티(3rd-party) 모니터링 시스템인 프로메테우스(Service Metric을 수집하는 별도의 Agent)를 통해 서비스 디스커버리(Service discovery), 메트릭 수집(Retrieval) 및 시계열 데이터베이스(TSDB, Time Series Database)를 통한 저장, 쿼리 엔진을 통한 PromQL 사용과 Alertmanager를 통해, 해당 Metric을 Dashboard로 확인하거나 HPA로 전송한다.
# event-simulator 도커 컨테이너를 실행하는데 무작위 이벤트를 생성한다.
docker run kodekloud/event-simulator # run -d 옵션 사용하면 로그 표시가 안된다.
# docker logs 명령으로 로그를 확인 할 수 있다.
docker logs -f ecf
# 파드 내 여러 커테이너가 있는 경우 이름을 명시해야된다.
kubectl logs –f event-simulator-pod event-simulator
참고
'STUDY > Data Engineering' 카테고리의 다른 글
| 12. CKA udemy 강의 정리 - Section 6 [Cluster Maintenance] (0) | 2023.01.14 |
|---|---|
| 11. CKA udemy 강의 정리 - Section 5 [Application Lifecycle Management] (0) | 2023.01.12 |
| 9. CKA udemy 강의 정리 - Section 3 [Scheduling] (0) | 2023.01.07 |
| 8. CKA udemy 강의 정리 - Section 2 [명령형 접근법/선언형 접근법] (0) | 2023.01.06 |
| 7. CKA udemy 강의 정리 - Section 2 [Namespace] (1) | 2023.01.06 |