![[추천시스템] Learning To Rank(LTR)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FbkITPa%2Fbtr88q9JMqp%2FAAAAAAAAAAAAAAAAAAAAAI2EDXKZb0di7jOLgZAeCh5fpR2kqnCMZf1st9QUpbZU%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1774969199%26allow_ip%3D%26allow_referer%3D%26signature%3DIrfOPch4R8GaECS1BfoOhjd%252ByXY%253D)
1. LTR이란?
추천 시스템에 있어서 추천 방식을 2가지로 나눠보자면 아래와 같다.
- 평점 예측 : rating matrix prediction
- 랭킹 예측: top-k prediction
평점 예측과 랭킹 예측의 가장 큰 차이는, 랭킹 예측이 유저가 더 선호할 만한 상품을 우선 순위에 랭킹하여 선호 관계를 잘 맞추는게 중요하다는 것이다.
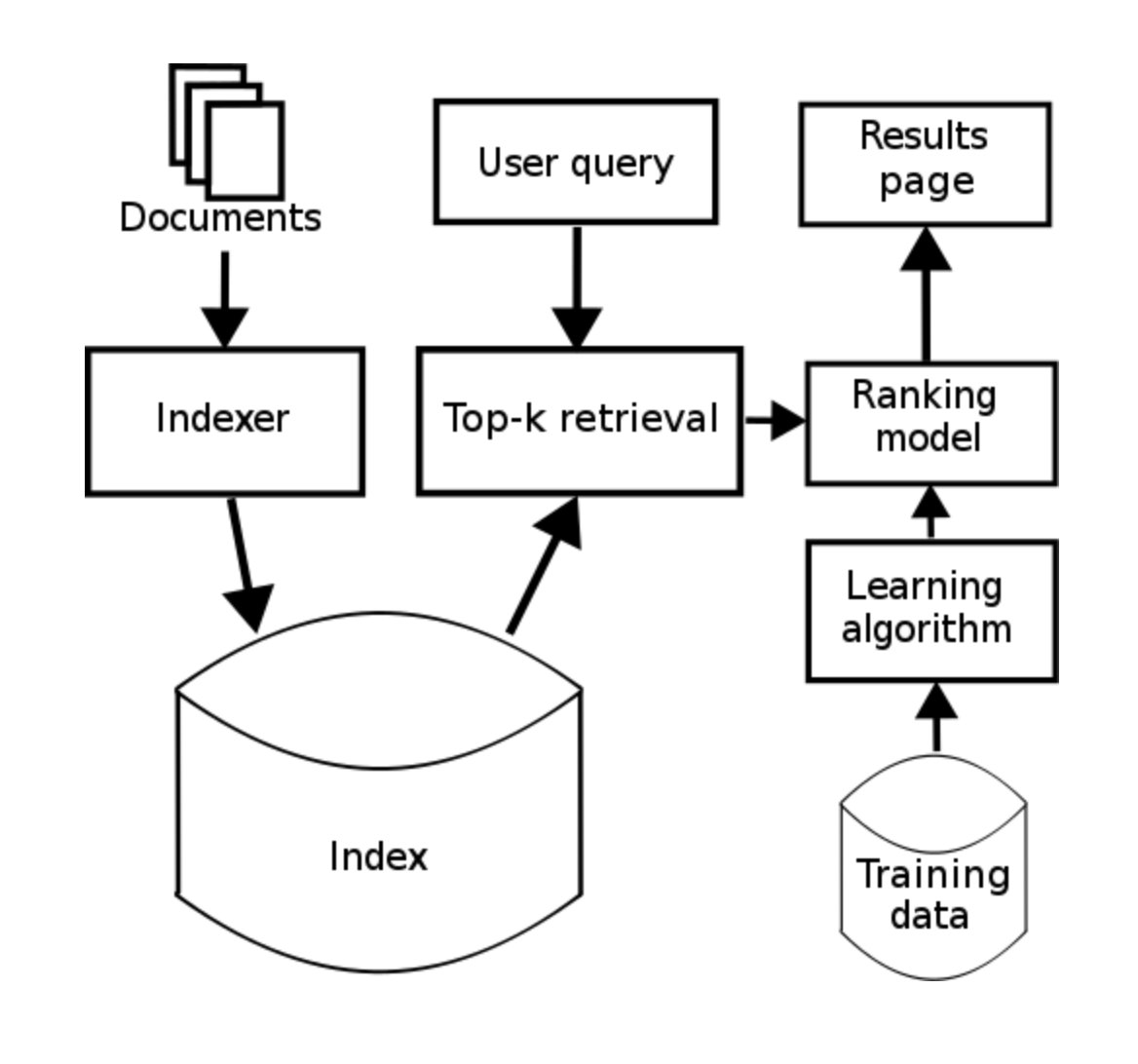
n개의 유저에 대해서 각 item에 대한 m개의 feaure가 정해지고 n개의 relevance score로 학습 데이터를 생성하게 된다. 이때 학습 시킨 모델에 테스트 데이터를 넣어 relevance score를 예측하게 된다. 예측값의 정의에 따라 랭킹이 결정 되기 때문에, learning to rank에서 가장 중요한 점은 어떠한 손실함수(loss function)를 사용하여 모델을 학습시키는가가 된다.
🐳 랭킹에 사용되는 metric에 대한 정보는 이전 게시글을 참고
([추천시스템] 성능 평가 지표(pyspark) - Precision, Recall, Map, NDCG)
2. loss를 정의하는 방법들
Point-wise
예측값과 정답값의 차이만 계산하는 방법.
전통적인 회귀나 분류 문제와 크게 다를게 없고, 사용하고 있는 ML 모델들을 그대로 적용할 수 있다는 장점이 있다. 하지만 전체 데이터를 활용하는 것이 아니기에 최적의 결과를 얻지 못할 수도 있다.
- 예: MSE(Mean Square Error)

Pair-wise
한번에 2개의 아이템을 고려해 비교하는 방법 (Ranking의 ground truth와 가장 많은 pair가 일치하는 optimal한 순서를 찾아내는 것)
모델이 직접 순위를 학습하고, 명시적인 데이터 없이도 Pairwise binary label를 얻기 때문에 새로운 label을 만들 수 있다.
다만 순위를 직접 최적화를 하는 것이 아니라는 단점이 있다.
- 예: include hinge loss, logistic loss
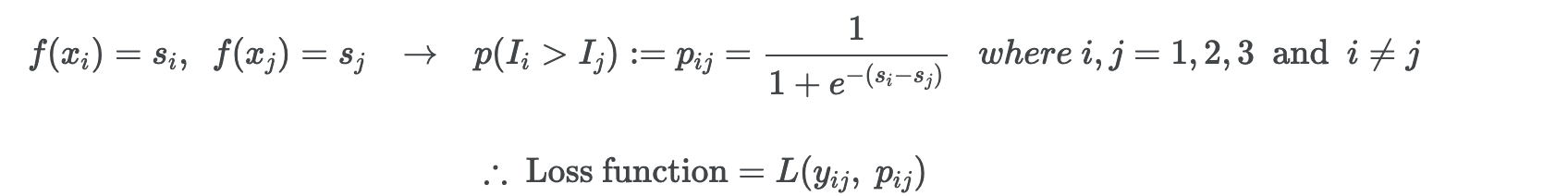
List-wise
Loss function에서 pred row로 주어진 top N개의 아이템을 모두 고려하여 전체 랭킹을 최적화하는 방법.
3개의 방법론 중에 가장 뛰어난 성능을 보이지만, 연산량이 많다는 단점이 있다.
list wise에서는 LambdaRank를 가장 많이 활용하는데, NDCG를 직접 최적화 하는 알고림이다. NDCG와 같은 ranking loss들은 불연속(discontinuous)하여 그라디언트를 정의할 수 없는데 LambdaRank는 NDCG를 최적화할 수 있는 그라디언트를 설계하여 학습하게 된다.
- 예: normalized discounted cumulative gain (NDCG), mean reciprocal rank (MRR)
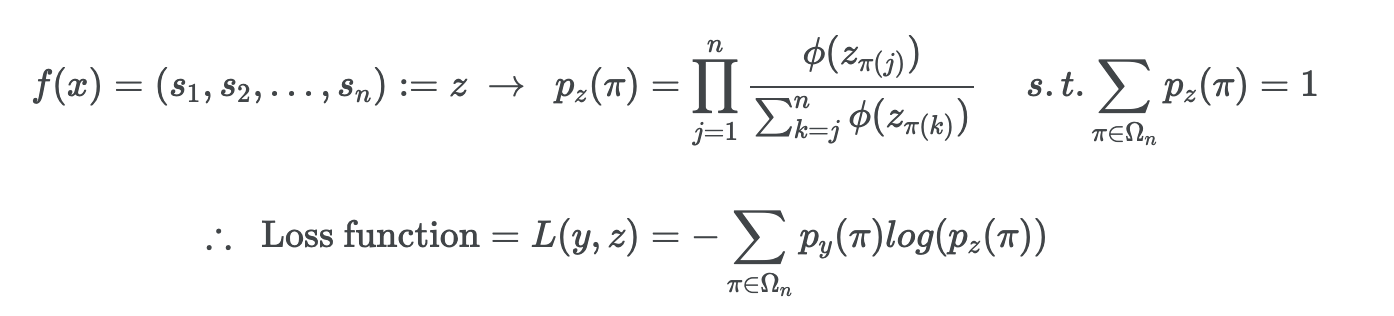
'개발 > ML&DL' 카테고리의 다른 글
| 1. 군집화 (Clustering) - 유사도 측정 기법 (0) | 2023.04.23 |
|---|---|
| [추천시스템] Learning To Rank(LTR) (1) | 2023.04.09 |
| [추천시스템] 성능 평가 지표(pyspark) - Precision, Recall, Map, NDCG (3) | 2023.03.11 |