![[정리] 최신 데이터 인프라 이해하기_#5 Spark, Python, Hive](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FbB9ryl%2FbtrqN4vMQpR%2FAAAAAAAAAAAAAAAAAAAAAHuk44yIyU6kFozGleArHo1eyOi6YLPlqLQQdcnoJIP_%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1774969199%26allow_ip%3D%26allow_referer%3D%26signature%3DDwinCTX4ttinJjgKMK%252Fh5dqC3CA%253D)
Ingestion and Transformation
- spark 플랫폼은 데이터를 가져와서 처리하는데, spark sql처리를 하든 streaming를 하든 머신러닝을 하든 대규모로 처리하게 해주는게 spark이다. (python, scala 등 다양한 언어 지원)
- 배치쿼리 엔진 hive랑 연결해서 다양한 데이터 소스 가져다가 처리 가능함.

4. Spark Platform
- 워크 플로우 매니저에서는 task를 실행하는데, 그 task가 빅데이터를 다루기 위해선 수백대 수천대 기기에서 분할해서 분석하는 작업이 이루어져야한다. 에어플로우는 분할해서 분석처리하는 것은 아니고, task를 수행하는 엔진이기 때문에 spark를 통해 빅데이터 분석작업을 시킨다. (spark가 생긴 후 에어플로우가 생겼다.)
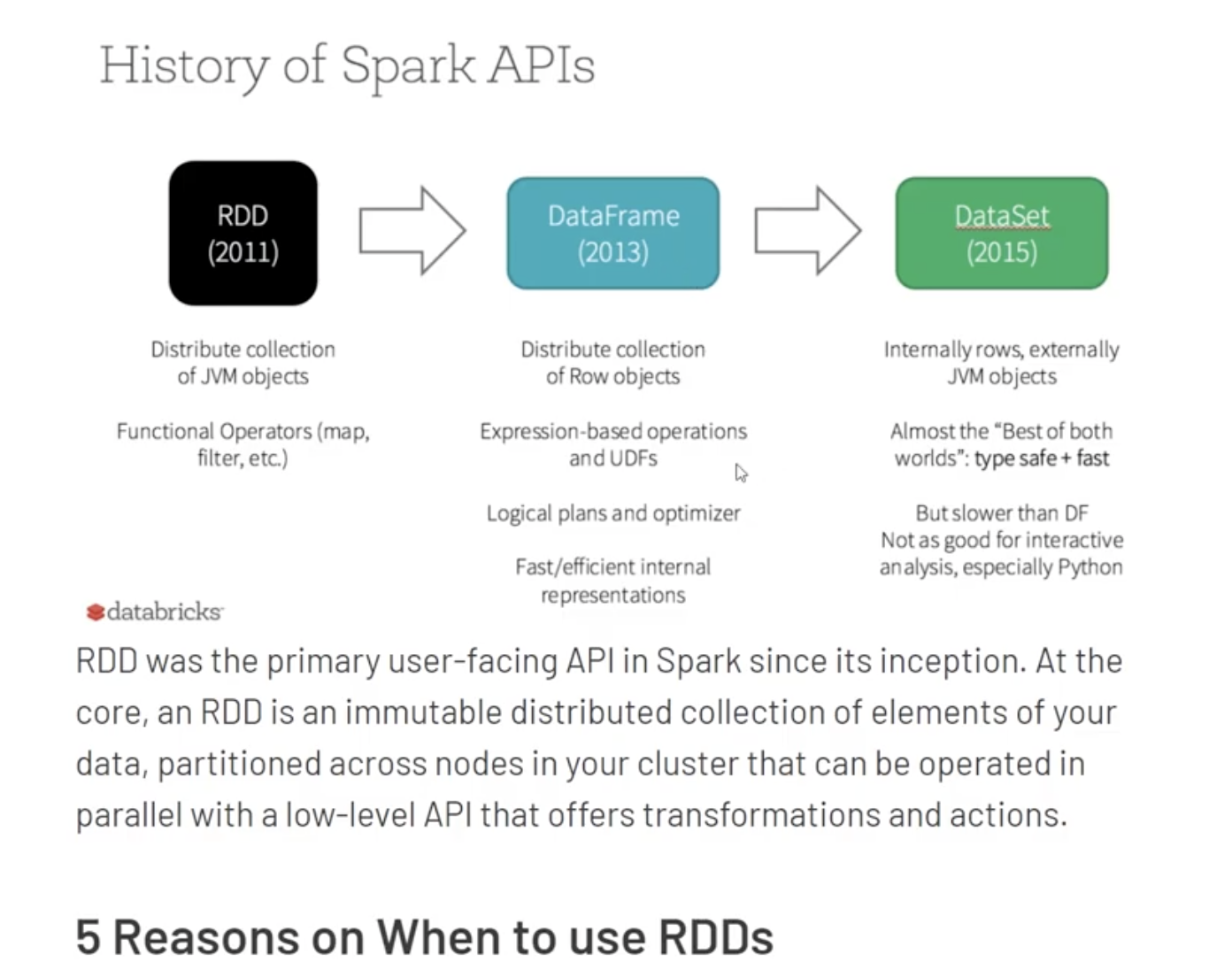
- spark: 대규모 데이터 처리를 위한 통합 분석 엔진, 오픈소스 분산 다목적 클러스터 컴퓨팅 프레임워크
오픈소스로 된, 분산처리를 위해 다목적 범용으로 쓰기 좋은 클러스터 컴퓨팅 프레임워크

📌map reduce란? (더보기)
| map reduce란? 어떤 일이 있을 때 Master가 work를 쪼개서 여러대의 서버에 나눠주면, 나눠서 일을 처리한 후 다시 서버로 보내 -> 다시 맵하고 리듀스를 반복하는 것이 하둡의 기본 구조. spark보다 느림. |
📌spark가 왜 빠를까? (더보기)
RDD가 스파크의 핵심인데 이에 대해 잘 설명한 자료: https://www.slideshare.net/yongho/rdd-paper-review
Spark 의 핵심은 무엇인가? RDD! (RDD paper review)
요즘 Hadoop 보다 더 뜨고 있는 Spark. 그 Spark의 핵심을 이해하기 위해서는 핵심 자료구조인 Resilient Distributed Datasets (RDD)를 이해하는 것이 필요합니다. RDD가 어떻게 동작하는지, 원 논문을 리뷰하며
www.slideshare.net




ram은 중간에 꺼지면 날라가니





SPARK는 RDD 기반으로 빠르게 구현됨.
스파크의 코어는 rdd를 처리하는 로직이고. rdd위에 spark sql, straming, MLlib, Graphx 붙음
Spark SQL: RDD기반으로 SQL 문장 처리, RDD는 여러대의 서버에 나눠서 빨리 처리하는 로직인데 그 위해 sql을 얹음. 이걸 처리하기 위해 rdd 기반의 새로운 데이터 구조를 만든다.
Streaming: RDD기반의 스트리밍 처리 객체


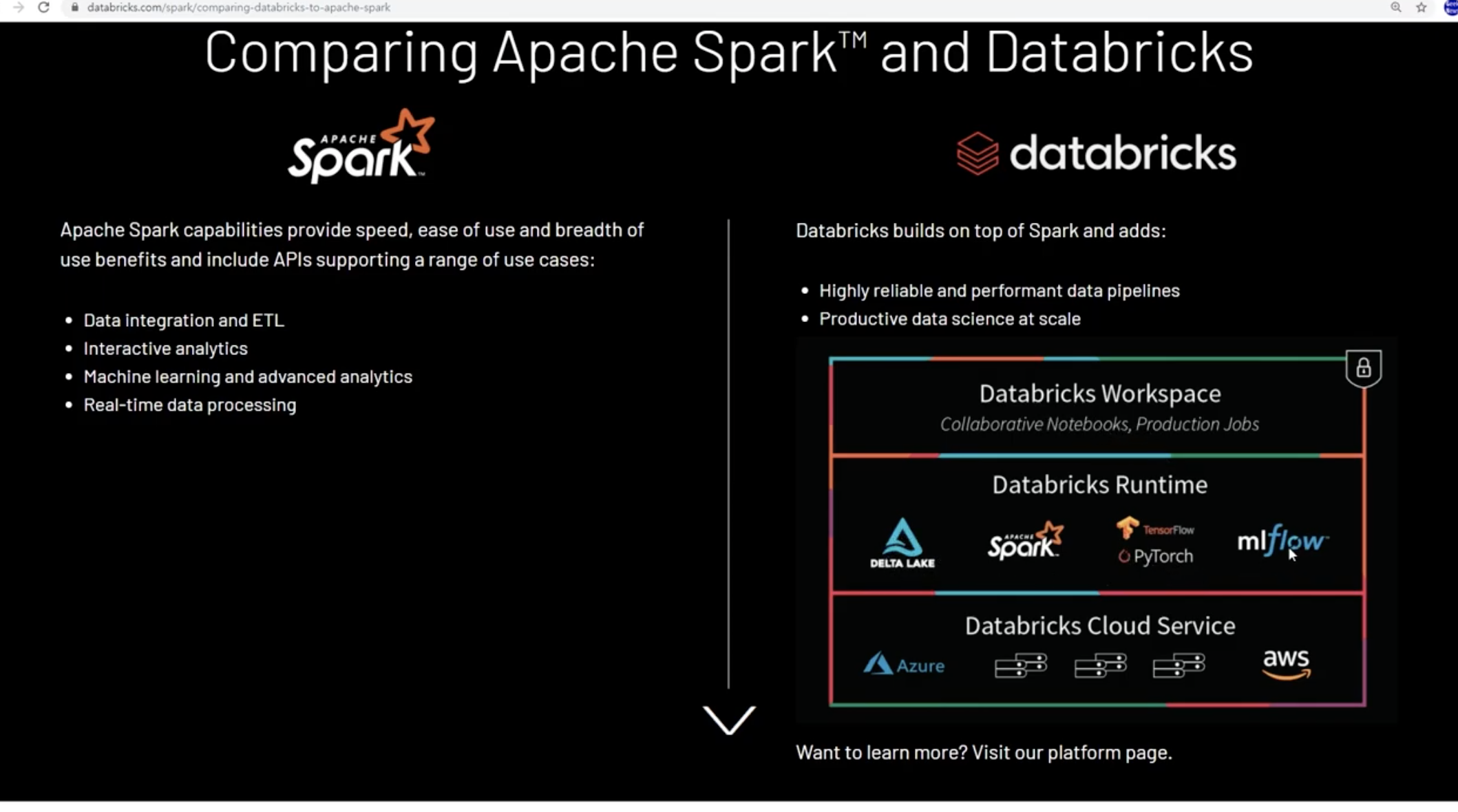
- databricks: spark가 기본엔진
스파크가 자동차 엔진이라면 데이터브릭스는 자동차이다.
스파크를 쓴다고하면 구현을 해야되는데 데이터 브릭스를 솔루션으로 하여 스파크를 구성할 수 있다. 실제로 그냥 스파크를 구성해서 돌린것보다 빠르다.

- amazon EMR: 스파크, 맵리듀스 다 돌릴 수 있게 만든 아마존의 클라우드 데이터 플랫폼. 데이터 브릭스랑 비슷


5. Python Libs
- pandas: (python data analysis) 패널 데이터에서 이름이 왔다. 판다스는 이런 페널 데이터를 분석하는 도구. 데이터 프레임이라고 하는 형태로 테이블 데이터를 처리한다. *패널 데이터: 여러 객체들을 복수의 시간에 거쳐 추적하는 데이터.
SQL이랑 비슷하나 개발자가 아닌 사람도 데이터에 접근할 수 있게 해주는 언어라서 일반적인 접근방법
pandas는 개발자가 함수를 호출해 조작할 수 있게 만든 구조. 더 강력하고 빠른 처리 가능.
- Boto3: 아마존 리소스를 사용하게 해주는 api
python으로 아마존 웹 서비스에 접속해서 수많은 클라우드 서비스 ec2, s3 등에 접근 가능하게 해주는 라이브러리
- DASK: python을 native scaling하는 라이브러리로 병렬처리가 가능하게 해줌
numpy, padnas, scikit learn 여러대의 서버에서 병렬처리해서 실행해줌.

- RAY: dask는 중앙 관리, ray는 분산 bottom-up 스케줄링. dask보다 빠름.
dask에서 task latency와 throughput을 하기위해 스케쥴링을 바꾼것이 ray이다.
둘의 차이점은똑같이 여러대의 서버에서 Python 코드를 분산실행하는데, dask는 데이터 사이언스에서 데이터프레임으로 분산데이터 처리할때, ray는 여러대의 서버에서 머신러닝을 돌릴때 나눠서쓴다.
6. Batch Query Engine

- HIVE: 배치쿼리 엔진 하이브, 하둡위에 올라와 있는 HDFS 있는 데이터를 쿼리하기 위한 엔진.
하둡을 통해 데이터를 쿼리하려면 맵리듀스 잡을 짜야되는데, 하이브는 sql를 작성하면 sql잡이 맵리듀스 잡으로 변환되어 하둡에 있는 데이터를 읽어와서 처리하게 되는 도구.
📌spark sql이 있는데 왜 spark 플랫폼과 하이브가 연결되어있어?(더보기)
spark sql이 있는데 왜 spark 플랫폼과 하이브가 연결되어있어? (특장점) 하이브는 메타 스토어를 통해서 자기가 연결되어 있는 데이터베이스의 메타데이터를 지니고 있다. 이 메타스토어를 spark가 그대로 이용가능하다. 하이브는 thrifit, JDBC, ODBC 와 같은 다양한 데이터베이스와 이미 연결되어있는데, 이걸 spark를 이용해서 쓰게되면 하이브를 실행하는 엔진으로 spark를 쓴다라고 이해할 수 있다. 그럼 더 빠르게 하이브 쿼리를 spark를 이용해 실행할 수 있게 되었다. spark가 hive를 대체하기 보다는, spark를 설치하고 기존의 HDFS에 있는 hive로 연결되어 있는걸 같이 사용하는 것. |
'STUDY > Data Engineering' 카테고리의 다른 글
| [정리] 최신 데이터 인프라 이해하기_#7 - Kafka Streams, kSQL, ksqlDB, Apache Flink, Spark Structured Streaming (0) | 2022.01.22 |
|---|---|
| [정리] 최신 데이터 인프라 이해하기_#6 Kafka, Pulsar, Kinesis (0) | 2022.01.16 |
| [정리] 최신 데이터 인프라 이해하기_#4 데이터 모델링과 워크플로우 매니저 (0) | 2022.01.15 |
| [정리] 최신 데이터 인프라 이해하기_#3 ETL/ELT 도구들 (0) | 2022.01.15 |
| [정리] 최신 데이터 인프라 이해하기_#2 데이터 소스 (0) | 2022.01.15 |