[hadoop] Hadoop Ecosystem
하둡 에코 시스템
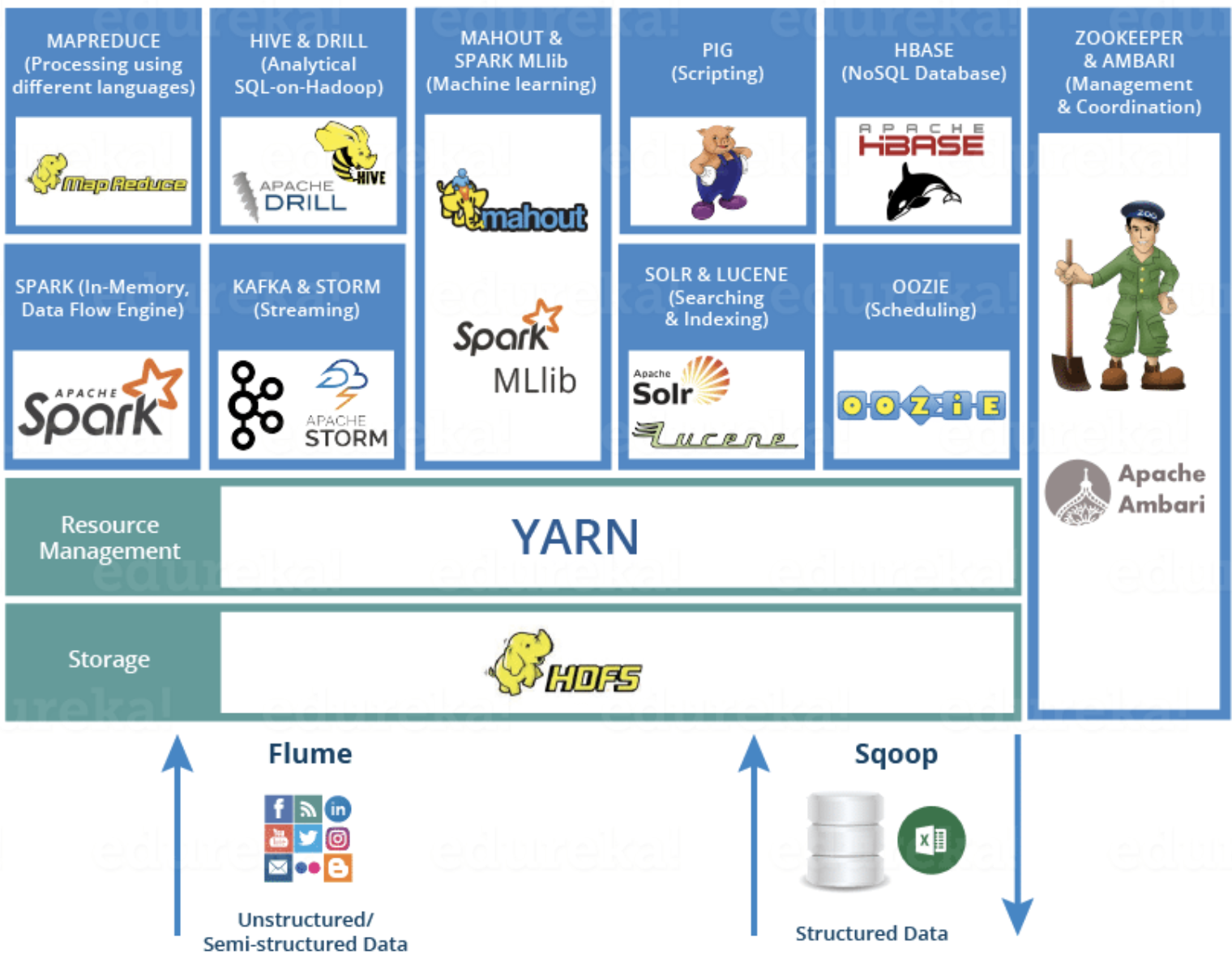
하둡 분산처리 시스템 (HDFS)과 MapReduce 프레임워크(코어 프로젝트)로시작했으나 여러 데이터 저장, 실행 엔진, 처리 등 다양한 하둡 생태계 전반을 포함하는 의미로 발전하고있다.
하둡 생태계에는 어떤 프로젝트들이 있을까? ▼
HDFS
하둡 네트워크에 연결된 기기에 데이터를 저장하는 분산형 파일 시스템. 여러 저장소에 대용량 파일을 나워서 저장한다. 그리고 여러 서버에 중복해서 저장하기 때문에 하나의 서버가 소실되더라도 복구할 수 있어 안정성을 높인다.
YARN (Yet Another Resource Navigator)
hadoop 2.0에서는 클러스터의 자원을 관리하기 위한 시스템으로 yarn이 추가되었는데, mapreduce에서 하던 일을 분산해서 하기 위해 추가되었다. 자세히 말하자면 YARN은 Resource Manager와 Node Manager 2 가지 유형의 실행 데몬을 통해 핵심 서비스를 제공하게 되는데,이는 Hadoop 1.0에 있는 JobTracker와 TaskTracker를대신해 등장한 개념이다.
MapReduce
대용량 데이터를 분산/병렬 컴퓨팅 환경에서 처리하기 위해 제작된 데이터 모델. 큰 데이터가 들어왔을 때, 데이터를 특정 크기의 블록으로 나누고 각 블록에 대해 Map Task와 Reduce Task를 수행한다.
ZooKeeper
분산 환경에서 서버 간의 상호 조정이 필요한 다양한 서비스를 제공하는 시스템.
HBase
NoSQL의 한 종류.
Kafka
데이터 스트리밍을 실시간으로 관리하기 위한 분산 시스템.
Spark
대규모 데이터 처리를 뺴른 속도로 실행시켜주는 엔진. 병렬 애플리케이션을 쉽게 만들 수 있게 해주고 파이썬, 자바, 스칼라를 사용할 수 있다.
Hive
하둡 기반의 데이터 솔루션. SQL과 유사한 언어를 제공하여 쉽게 데이터를 분석할 수 있게 해준다.
Cassandra
MongoDB같이 하둡 생태계에서 사용할 수 있는 NoSQL 데이터베이스
Pig
High leverl programming API로 파이썬, 자바 같은 것을 할 줄 모르더라도 SQL과 유사한 형태로 데이터 분석을 할 수 있게 해줌
하둡 버전에 따른 아키텍쳐의 변화
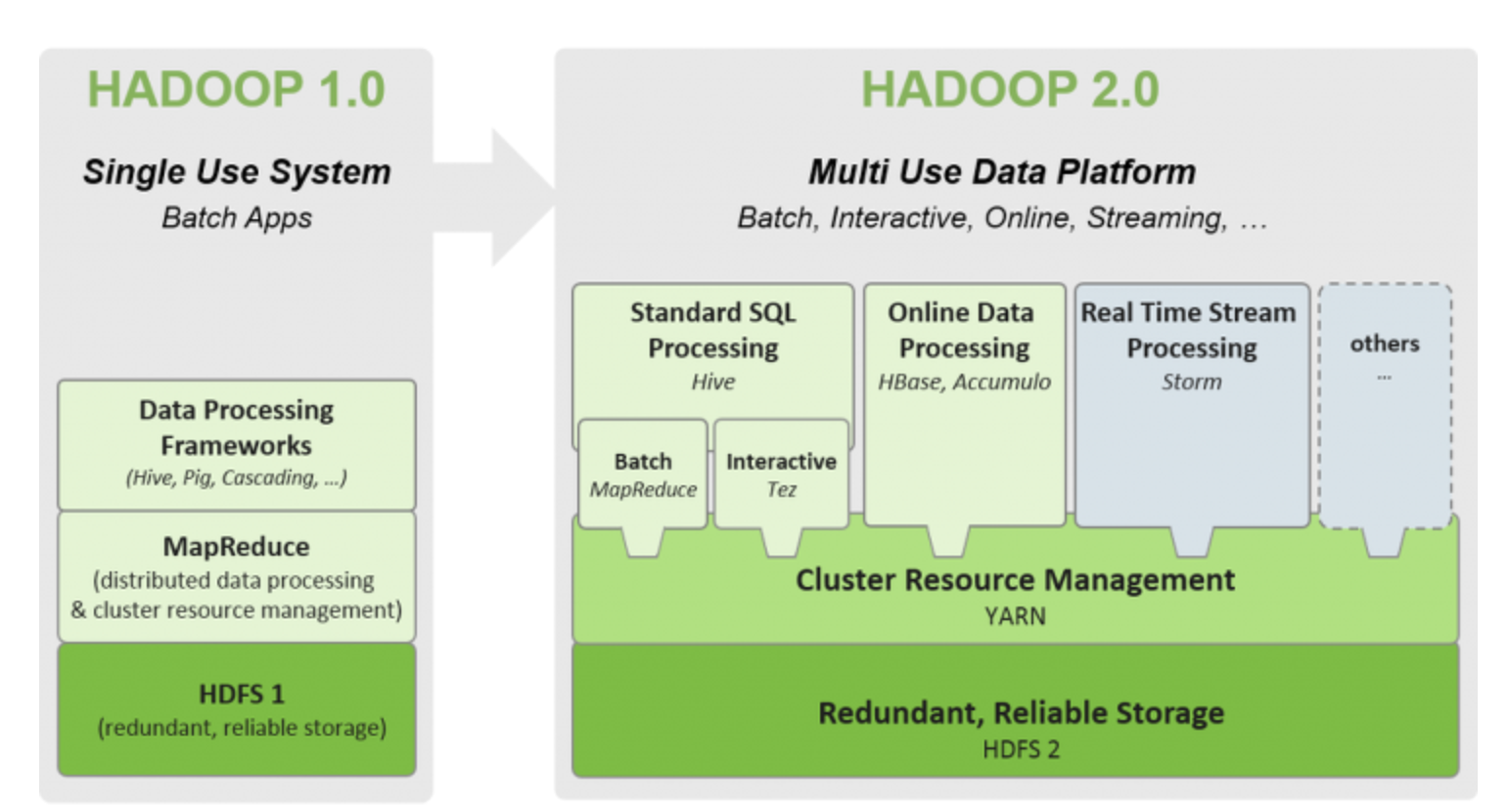
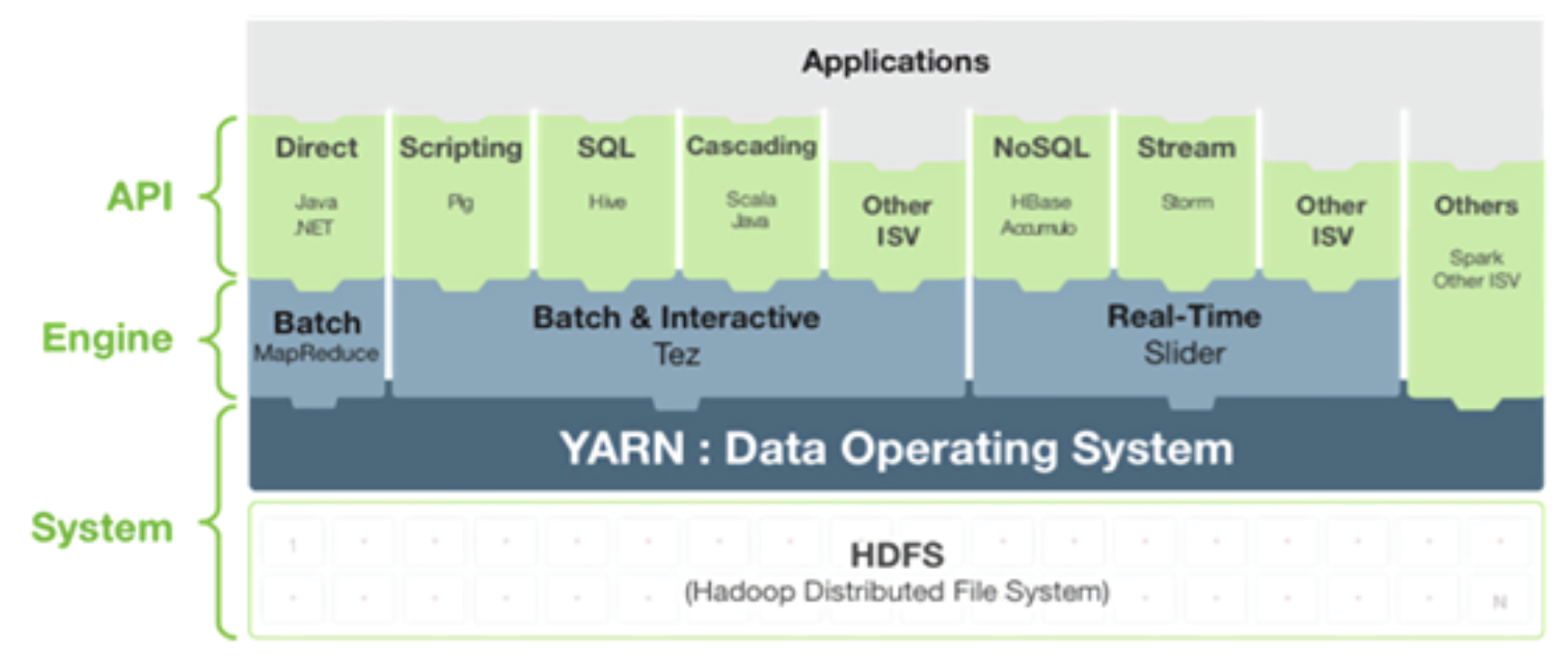
Hadoop 2.0에서는 YARN이 추가되었다.
- Hadoop1의 잡트래커가 리소스 관리, 잡 스케줄링을 동시에 처리하여 병목 지점이 되어 YARN 추가됨.
- YARN은 Resource Manager, Application Master가 리소스 관리, 잡 스케줄링을 담당
즉, YARN의 기본 아이디어는 JobTracker이 감당했던 일인 자원 관리와 job Scheduling / monitoring을 서로 나누는것이다.
| Hadoop 1.0 | Hadoop 2.0 | |
| 고가용성 (High Availability) |
▸ NameNode는 SPOF (Single Point Of Fainure,단일 고장점) |
▸ 고가용 공유 스토리지를 활용한 NameNode 이중화(Active-Standby) ▸ 주키퍼를 이용한 리소스매니저 이중화 |
| MapReduce /YARN | ▸ 최대 4,000개 노드에서 동작 | ▸ 최대 10,000개 노드에서 동작 ▸ YARN: 다양한 알고리즘 적용 가능 ▸ 그래프처리:(Google)Praegel, (Apache)Giraph ▸ 병렬처리 표준 메세지 인터페이스: ▸ MPI(Message passing interface) |
| HDFS1/HDFS2 | ▸ WebHDFS REST ▸ 단일 HDFS Federation ▸ 단일NameNode구성, 단일 NameSpace |
▸ HDFS NFS-v3 접근 지원 ▸ HDFS Caching ▸ 다중 NameNode 구성 ▸ NameNode별 NameSpace 관리 ▸ 계층 스토리지(Tiered Storage)지원 |
| 분산처리환경 | ▸ MapReduce | ▸ YARN기반의 다양한 분산처리 환경 제공 ▸Tez, HBase, Giraph, Spark, Storm 등등 ▸ MR 잡외에 Spark, Hama, Giraph 등 다른 분산 처리 모 델도 수행 가능 |
하둡과 스파크
하둡(Hadoop)이란?
대용량의 데이터를 분산처리 할 수 있는 자바 기반의 오픈 소스 프레임워크. 하나의 대형 컴퓨터를 활용하여 데이터를 수집, 처리하는 대신, 하둡 서버가 설치된 다른 상용 하드웨어와 함께 클러스터링 하여 대규모의 데이터 세트를 병렬적으로 분석할 수 있다.
-> 간단한 프로그래밍 인터페이스를 통해 클러스터 환경에서 대용량 데이터에 대한 분산 처리하는 프레임 워크
스파크(Spark)이란?
빅데이터 분산 처리 프레임워크인 spark는 하둡 위에서 동작할 수 있는 인메모리 프로세싱 엔진이다 (하둡과 맵리듀스 스파크의 관계)
하둡이 끼친 영향
이것이 중대한 의의가 있는 이유는 하둡 덕분에 당시까지 대세였던 상용(proprietary) 데이터 웨어하우스(DW) 솔루션과 폐쇄형 데이터 형식에 실질적인 대안을 제시해주었기 때문입니다.
하둡이 도입되면서 기업에서 엄청난 양의 데이터를 저장, 처리할 능력을 신속히 확보할 수 있게 되었고, 컴퓨팅 파워를 증가하고 내결함성, 데이터 관리 유연성, DW에 비해 저렴한 비용은 물론 뛰어난 확장성까지 얻게 되었습니다. 궁극적으로 Hadoop은 빅데이터 분석 분야의 향후 개발을 위해 길을 개척했다고 볼 수 있습니다. Apache Spark가 가장 대표적인 예입니다.
참고 | 하둡 databricks
spark는 하둡과 꼭 같이 써야하는 건가?
스파크는 기본적으로 클러스터의 각 머신에 JVM과 아파치 스파크 프레임워크만 있으면 되는 독립형 클러스터 코드로 실행이 가능하다. 그러나 작업자를 자동으로 할당하기 위해 더 강력한 리소스 또는 클러스터 관리 시스템을 활용하고자 하는 경우가 많다. 엔터프라이즈에서는 이를 위해 보통 하둡 얀(Hadoop YARN)에서 실행하지만 아파치 메소스(Mesos), 쿠버네티스(Kubernetes), 도커 스웜(Docker Swarm)에서도 아파치 스파크를 실행할 수 있다. (참고: 하둡을 제압한 빅데이터 플랫폼" 아파치 스파크란 무엇인가)
예) 스파크는 하둡이 사용하는 파일 시스템인 HDFS (Hadoop Distributed File System) 의 데이터를 읽어올 수도 있고, 반대로 데이터를 쓸 수도 있다.
SPARK
- 스파크는 HDFS 에 저장된 데이터를 하둡 코어 라이브러리를 호출함으로써 메모리로 불러온 후, 변환 및 계산 등을 거쳐 최종 원하는 결과물을 산출합니다. 스파크는 인메모리 프로세싱을 하기 때문에 Disk I/O 가 많이 일어나는 하둡의 맵-리듀스보다 특정 작업 (ex. multi-pass map reduce)에서는 더 빠르게 수행될 수 있습니다.
- 스파크는 여러가지의 분산 데이터베이스나 파일 시스템을 수용할 수 있습니다. 하둡 뿐만 아니라 카산드라를 사용을 할 수도 있습니다. 카산드라는 CQL (Cassandra Query Language) 이라는 고유의 SQL 문법이 있는데, 이는 SQL 의 서브셋으로 다양한 데이터 추출을 이용하기가 힘들다고 알려져 있습니다. 카산드라에 스파크를 결합해 추가적인 데이터 프로세싱을 사용할 수 있기 때문에 카산드라 자체만을 통해 못하는 일을 할 수 있습니다.
- 스파크의 한 가지 장점은 stream processing 이라고 하는 실시간 데이터처리 입니다. 스파크는 실시간 데이터 처리를 위해 세팅이 될 수 있고, micro-batches 단위로 데이터 프로세싱을 수행할 수 있으며, 결과를 하둡 HDFS, 카산드라 같은 파일 시스템에 저장할 수 있습니다.
+ (참고) 쿠팡에서는 spark job에 hive table 활용하는 구조에서 hBase로 변경했다고 한다.
+ (참고) LINE 쇼핑에서는 데이터 히스토리를 관리하기 위해 HBase를 사용
MapReduce/RDD
맵리듀스 느리다는거 알겠는데 왜 RDD를 써야하나?
맵리듀스는 자바 프로그램일 뿐만 아니라, 일까지 직접 관리해야한다.
HDFS에 저장된 데이터를 쓰려면 무조건 맵리듀스 방식을 고수해야되기 때문에 아래와 같이 복잡한 과정을 거쳐야한다.
편의점에 껌 하나 사려는데 껌 공장까지 자서 품질, 개수 배분, 포장까지 해야되는 느낌. 껌 하나 사려고 껌 공장에 취직해야한다.
하지만 위에서 언급했던 하둡의 2.0 버전에서는 이러한 문제점 해결을 위해 YARN아키텍쳐가 등장했고 YARN은 일을 관리해주는 역할을 분담하게 되었다. 즉, 껌을 사러가면 편의점에 들어온 껌만 사면 된다는 얘기다. 나머지는 껌 공장 직원인 YARN이 알아서 일을 처리해준다.
맵리듀스는 하둡에서 데이터를 처리하기 위해 작동하는 어플리케이션 중 하나가 되었다. (참고: mapreduce와 yarn)
RDD (Resilient Distributed Datasets)
Spark = RDD + Interface -> 분산 변경 불가능한 객체 모임
spark의 모든 작업은 새로운 RDD를 만들거나 존재하는 RDD를 변형하거나 결과 계산을 위해 RDD에서 연산하는 것을 표현하고 있다.
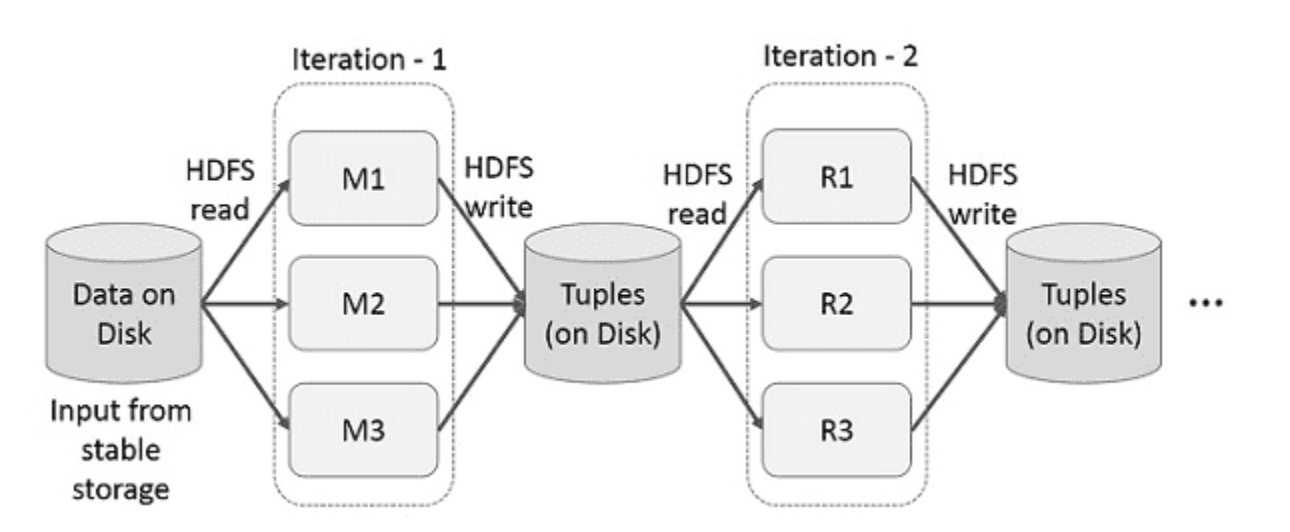
대용량 데이터 처리 프레임워크인 hadoop에서 사용하던 map reduce의 저장방식은, 데이터 중간 과정을 DISK에 저장하고 읽는 구조(복제, 직렬화, 디스크 io 때문에 데이터 공유가 느려짐)이기 때문에 느려지게 된다. 때문에 RDD라는 메모리 저장 방식의 데이터 구조가 나오게 되었다.
스파크의 핵심 아이디어는 RDD(Resilient Distributed Dataset)이며, 메모리 내 처리 연산을 지원한다. 메모리에서 데이터 공유는 네트워크나 디스크보다 10~100배 빠르다. 다만 데이터를 램에 올린 이후에 fault-tolerant가 발생해도 문제가 없도록 memory 내용을 갱신하지 않고 read-only로 사용한 것이 RDD이다.
위 구조에서 동일하지만 hdfs에 접근하는게 아닌 memory에 보관하여 실행시간을 줄여준다.
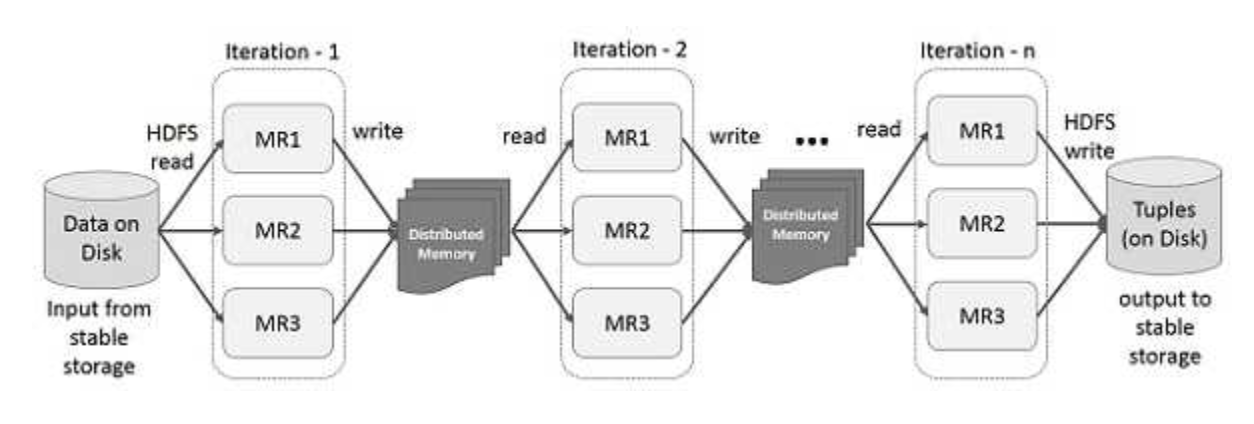
이하 궁금증

+ 하둡 시스템은 오버라이트가 안된다고 하면서 왜 rdd는 오버라이트가 안되고 데이터프레임은 됨?
-> 옵션이 있어서 그런 것 같음 원칙적으로는 Hadoop 파일 시스템은 기본적으로 이미 존재하는 파일을 덮어쓰지 않고, 기존 파일을 수동으로 덮어쓰는 옵션을 제공하지 않아 오버라이트가 안된다. (spark에서 파일 읽고 쓰기)
Spark/PySpark by default doesn’t overwrite the output directory on S3, HDFS, or any other file systems, when you try to write the DataFrame contents (JSON, CSV, Avro, Parquet, ORC) to an existing directory, Spark returns runtime error hence, to overcome this you should use
mode("overwrite") (참고)
+ rdd는 temporary일때도 읽힌다
1. RDD (Resilient Distributed Dataset):
RDD는 Spark의 기본 데이터 추상화 형태로, 불변성과 장애 내구성을 가지는 분산 데이터 컬렉션입니다. RDD는 여러 파티션으로 나누어져 클러스터의 여러 노드에 분산 저장될 수 있습니다. 기본적으로 RDD는 메모리 내에 저장되는 인메모리 데이터 구조입니다. 따라서 RDD의 작업은 메모리 상에서 수행되기 때문에 임시적인 결과를 메모리에 저장하고 재사용할 수 있습니다. 이러한 특징 때문에 중간 결과를 메모리에 캐시하고 재사용하는 것이 가능합니다.
2.Parquet 파일:
Parquet은 Hadoop 기반의 컬럼 지향 데이터 저장 형식 중 하나로, 대용량 데이터를 효율적으로 저장하고 처리하기 위해 설계되었습니다. Parquet 파일은 데이터를 열(Column) 단위로 압축하고 저장하며, 특히 데이터 스키마를 사용하여 열에 대한 메타데이터를 저장합니다. 이러한 특성으로 인해 데이터의 압축률이 높아지고 스키마 정보를 이용하여 데이터를 읽을 때 필요한 열만을 선택적으로 읽을 수 있습니다.
Parquet 파일은 데이터를 컬럼 단위로 저장하기 때문에 데이터가 분산되어 저장됩니다. 이러한 분산 구조로 인해 Parquet 파일은 RDD와는 다른 데이터 구조를 가지고 있으며, RDD와는 다른 방식으로 중간 결과를 처리하고 저장합니다. 보통 Parquet 파일을 읽거나 쓸 때는 전체 파일을 스캔하거나 쓰기 위해 임시적으로 메모리에 캐시하지 않습니다.
요약하자면, RDD는 메모리 내에 저장되는 인메모리 데이터 구조이기 때문에 중간 결과를 메모리에 캐시하고 재사용하는 것이 가능합니다. 반면에 Parquet 파일은 분산된 컬럼 단위로 저장되기 때문에 전체 파일을 스캔하거나 쓰는 방식으로 동작하며, 임시적으로 중간 결과를 메모리에 캐시하여 사용하는 것은 효율적이지 않습니다. 따라서 Spark에서는 Parquet 파일을 불러와서 중간 결과를 처리하는 것보다는 RDD를 활용하는 것이 더 효율적일 수 있습니다.
+ RDD overwrite하기
if fs.get(conf).exists(hadoop.fs.Path(output_path)):
fs.get(conf).delete(hadoop.fs.Path(output_path))
#이전엔 .delete(hadoop.fs.Path(output_path,True)+ textfile -> parquet (https://pearlluck.tistory.com/561)
-
더보기하둡 프로세싱에서는 저장 형태를 신경쓰지 않는 이유.
- 데이터가 큰 경우에는 parquet(열기반 압축)로 저장을 하였지만, 결국 IO(정렬, 재가공 등등) 를 많이 사용하는 팀에서 이점이 있는 것이지 파이프라인 거쳐서 ES떨구는 거니까 용량이 크던 작던 크게 상관은 없다. extract에 시간이 더 걸릴수도? - spark에서 왜 text(tsv, csv) 대신 binary로 파일을 다뤄야 하는가 -> 프로세싱타임 차이 + 바이너리 파일 디버깅 할 필요도 없음(참고 stack overflow)
- 32bit 컴퓨팅환경에서 cpu가 한번에 데이터 읽는 것은 4byte.
- text는 MAX_DOUBLE(1.7976931348623157E+308)의 경우 23자, 6번의 cpu-memory-disk 간 통신이 필요함.
반면 binary 는 8byte 안에 MAX_DOUBLE이 담긴다. 즉 2번의 통신이 필요하게되고, 이로 인해서 저장 용량도 단순히 4배 가까이 차이가 난다. - cpu가 데이터를 처리를 하는것은 01로 이루어진 binary값이어야 하는데
text의 경우 1.character뭉치를 모아서 2.double로 타입캐스팅 3. double type->byte code로 decoding 작업이 필요하게된다. 반면 binary는 이미 decoding 된 상태로 저장되어 있기때문에 읽으면 별도의 변환이나 디코딩 과정없이 바로 cpu에서 processing이 가능. - The other big issue is fixed-size vs. variable-sized records when doing random access. If records are fixed in size, then it is easy to go to the Nth record in a file. If they are variable in size, then you may have to read and parse records 1 to N-1 before reading record N. -> fixed size인 binary가 더 빠르다는 내용
- CSV,JSON : 우리가 일반적으로 사용하는 TEXT기반의 파일 포맷으로, 사람이 읽을 수 는 있지만 압축이 되지 않았기 때문에 용량이 크다
- Parquet (Columna) : 스파크와 함께 가장 널리함께 사용되는 파일 포맷으로 바이너리 포맷을 사용한다. 특히 데이터 뿐만 아니라 컬럼명, 데이터 타입, 기본적인 통계 데이타등의 메터 데이터를 포함한다.CSV,JSON과는 다르게 기본적인 압축 알고리즘을 사용하고 특히 snappy와 같은 압축 방식을 사용했을때, 원본 데이터 대비 최대 75% 까지 압축이 가능하다. Parquet 포맷의 특징은 WORM (Write Once Read Many)라는 특성을 가지고 있는데, 쓰는 속도는 느리지만, 읽는 속도가 빠르다는 장점이 있다. 그리고 컬럼 베이스의 스토리지로 컬럼 단위로 저장을 하기 때문에, 전체테이블에서 특정 컬럼 만 쿼리하는데 있어서 빠른 성능을 낼 수 있다.
- Avro (Row) : Avro는 Paquet 과 더불어 스파크와 함께 널리 사용되는 바이너리 데이터 포맷으로 Parquet이 컬럼 베이스라면, Avro는 로우 베이스로 데이터를 저장한다. Avro는 바이너리로 데이터를 저장하고 스키마는 JSON 파일에 별도로 저장한다. 그래서 사용자가 바이너리 파일을 이해할 필요 없이 JSON 만으로도 전체적인 데이터 포맷에 대한 이해가 가능하다.
(Apache Spark #1 - 아키텍쳐 및 기본 개념)
+ rdd와 df는 왜 퍼포먼스 차이가 날까요?
df는 수행시에 카탈리스트 옵티마이저로 컴파일해서 유저코드 받아서 수행할 때 최적의 퍼포먼스 낼 수 있는 형태로 바꿔서 rdd로 내뱉는 구조이기 때문이다. (참고: [spark] 스파크 2.0의 성능개선-직렬화,off-heap,옵티마이저) 슬라이드 쉐어
참고
1. mapreduce와 yarn 개념에 대해서 참고 (하둡 생태계와 더불어 예시가 재밌음)
3. 스파크 처리 모델 RDD (참고해서 보충예정)
4. parquet란? (참고해서 보충예정)