Spark 이해하기(RDD, DAG, Lazy Evaluation)
MapReduce가 대형 데이터 분석을 쉽게 만들어주었다.
맵리듀스는 대규모의 일괄 처리에는 뛰어나지만
그러나 저지연 애플리케이션과 multi-stage한 머신러닝, 그래프와 같은 처리나 상호적이고 즉흥적인 쿼리는 해결하기가 어려웠다.
때문에 그래프 데이터 분석 엔진(pregel)인 특수 목적 분산 프레임워크가 나왔지만 뭔가 근본적인 접근 방법이 없을까?
MapReduce가 학습 횟수가 많은 이유는 각 iteration을 돌때마다 스테이지간의 자료 공유가 HDFS(하둡)를 거치기 때문일거라 생각해
이를 RAM으로 해결하자는 효율적인 Data Sharing 도구를 기안해냄.
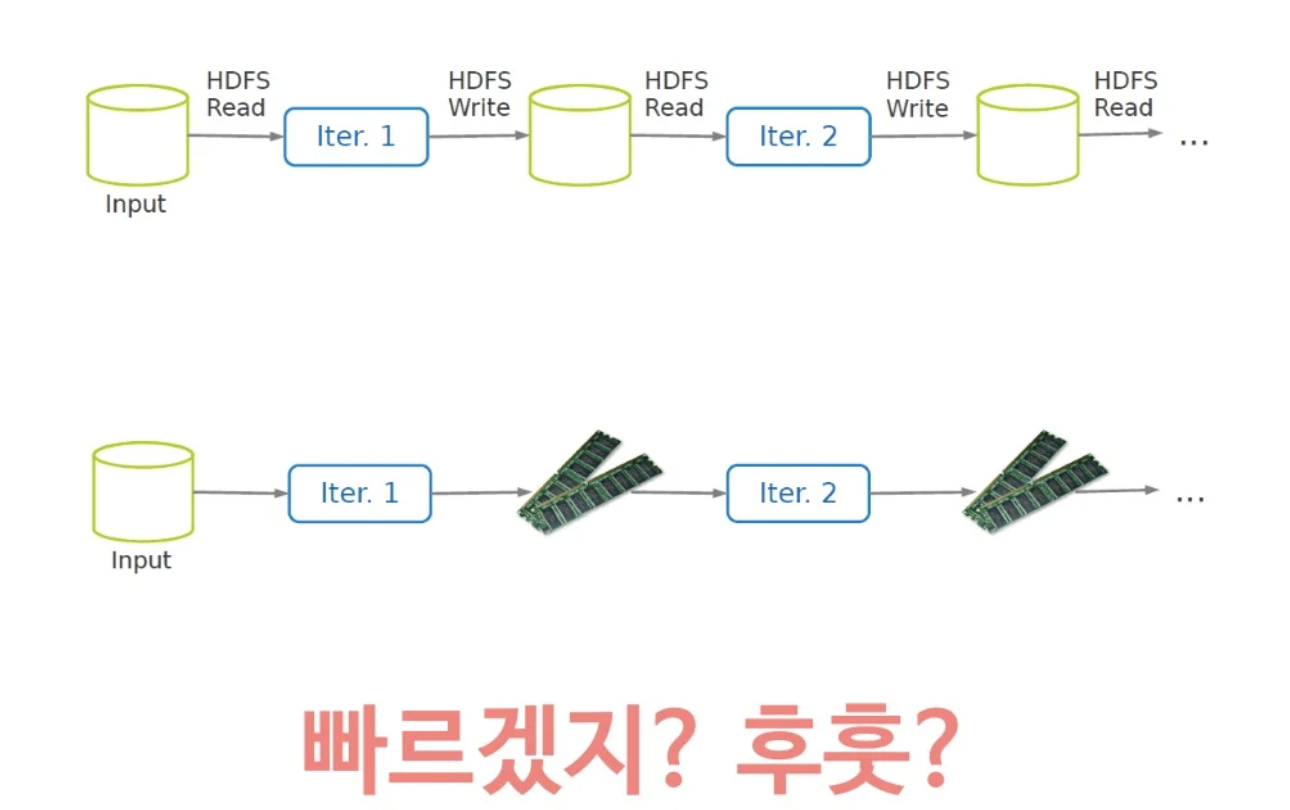

그러나 RAM은 휘발성이므로 중간에 잘못되면 날라간다. 그래서 어떻게하면 효율적인 램스토리지를 만들수있을까에 대한 고민을 하기 시작함.

그런데 GFS(HDFS)는 수정이 안되는 파일 시스템, 무조건 쓰며 달리는 파일 시스템 개념으로 많은 것을 단순화 시켜 큰 시스템을 만들어냈다. (때론 상식을 뒤집을 때 혁신이 일어난다.)
때문에 여기서 RAM을 read-only로 써볼까?라는 아이디어를 가지게 되었고 이것이 바로 RDD(Resilient Distributed Datasets)이다.

스파크에서는 자료가 어떻게 변해갈지를 그리는 와중(transformation)에는 실제 계산이 일어나지 않는다!
directed acyclic graph(DAG)로 디자인 해 나가는 것.
RDD operator
때문에 2가지 RDD operator가 있다!
바로 transformations & actions
- transformations은 (map, reduce, join 등등) 데이터의 이합집산, 지지고 볶는 흐름 단순히 map, reduce에만 있던 MR보다 명령어가 풍부하다.
- Actions는 실제로 말미에 '자 모든 transformations된 결과를 내놓아라~"하는 명령 즉, tras->trans-> ... ->trans->action 이런 구성이 됨.
lazy-execution
위에서 말한 것 처럼, 인터프리터에서 transformation들로 코딩하고 있으면 아무일도 생기지 않는다. 때문에 action에 해당하는 명령어가 불리면 그제서야 실행하는 과정을 lazy-execution이라고 칭한다.

2가지 타입의 dependency

narrow dependency - 책상 한자리에서 다 처리할 수 있는일은 모아서 해!
- 해당 작업이 다 한 노드에서 돌 수 있다. (네트워크가 안탄다, 메모리 속도로 작동해서 엄청 빠르다, 가지고 있는 파티션이 부셔져도 그 노드에서 복원가능)
wide dependency - 이 자료부터 저 자료까지 모든 책사엥 있는 자료 훓어와서 해!
- wide는 책상 돌아다니면서 모아서(여러 노드) 네트워크의 속도로 동작해서 좀 느림.
- 셔플이 일어나야 하는 친구들, 네트워크 타야됨, 부셔지면 망한다.(계산비용 비쌈), 그래서 추가로 checkpointing을 해줘야함.
(결론) narrow dependency를 잘써라!!!이지만 잡 스케쥴링을 해서 dag에 따라 계산해 나감

job scheduling
Spark Context 내에서 이루어지는 Job들의 경합과 우선순위를 제어할 수 있고, Dynamic Resource Allocation을 통해 Spark Context 간의 효율적 리소스 재분배가 가능하다.
- 스파크 애플리케이션은 여러 잡을 실행시켜 원하는 바를 달성한다.
- 스파크 잡은 task라고 하는 더 작은 실행 단위로 나뉜다.
- 이 태스크는 여러 익스큐터에게 작업 실행을 요청함으로써 병렬 처리가 가능하다.
- 태스크가 종료되면 결과를 받고 다른 태스크를 실행 요청하며, 잡의 모든 태스크가 완료될 때까지 작업 요청을 진행하게 된다.
- 잡의 모든 태스크가 종료되면 다음 잡을 실행할 수 있다.
- 선입선출, FIFO 구조이다.





Spark VS in-memory hadoop
RAM을 쓰니까 당연히 더 빠르겠지만 왜! in-memory HDFS를 쓰는 HadoopBinMem보다 빠른거야?
- hadoop의 소프트웨어 스택이 복잡하고 HDFS라는 파일 구조체 다루는데 기본요금 비쌈
- Bin을 계산하기 위해 java object로 돌리는데 또 계산 비용 듦. -> 스파크는 자바 오브젝트 상태로 계속 활용
- 애초에 메모리더라도 작업 반복할때마다 전부 썼다 읽었다하는데 빠를 수가 없다.
결론) RAM을 ROM처럼 사용해보기로함. (RAM이지만 한번쓰고 다시는 안고치는)
SPARK의 시작!
발표자료
https://www.slideshare.net/yongho/rdd-paper-review
Spark 의 핵심은 무엇인가? RDD! (RDD paper review)
요즘 Hadoop 보다 더 뜨고 있는 Spark. 그 Spark의 핵심을 이해하기 위해서는 핵심 자료구조인 Resilient Distributed Datasets (RDD)를 이해하는 것이 필요합니다. RDD가 어떻게 동작하는지, 원 논문을 리뷰하며
www.slideshare.net
논문원본
- 2012년 NSDI에 발표
- RDD -> 2012 NSDI best paper
https://www.usenix.org/system/files/conference/nsdi12/nsdi12-final138.pdf
